很多网站或者防火墙针对Selenium进行了检测,对程序控制的浏览器不予响应,导致我们的网页自动化无法运行。
可以通过这个网站进行检测 https://bot.sannysoft.com/

原因是webdriver有一些特征是完全可能被服务器端或防火墙检测到的。
传统的应对方法基本都失效了,比如stealth.js,cdp command等等。
undetected_chromedriver
undetected_chromedriver可以通过检测,但是如果你的程序大都是webdriver写的,迁移到undetected_chromedriver也是不小的工作量。
1 | import undetected_chromedriver as uc |
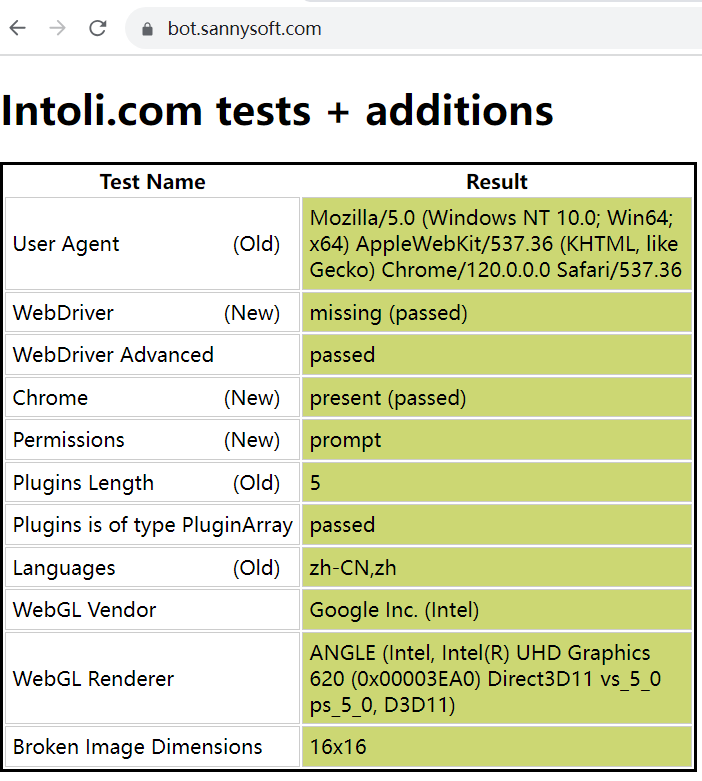
试试webdriver驱动firefox
顺利通过检测,为了避免以后firefox自动升级而driver不能适配,最好把firefox打包成portable版的。
以前webdriver编写的大部分代码不需要更改。
1 | from selenium import webdriver |
国产drissionpage,摆脱了对selenium的依赖,经测试顺利通过检测。
用 requests 做数据采集面对要登录的网站时,要分析数据包、JS 源码,构造复杂的请求,往往还要应付验证码、JS 混淆、签名参数等反爬手段,门槛较高,开发效率不高。 使用浏览器,可以很大程度上绕过这些坑,但浏览器运行效率不高。
因此,这个库设计初衷,是将它们合而为一,同时实现“写得快”和“跑得快”。能够在不同须要时切换相应模式,并提供一种人性化的使用方法,提高开发和运行效率。
除了合并两者,本库还以网页为单位封装了常用功能,提供非常简便的操作和语句,使用户可减少考虑细节,专注功能实现。 以简单的方式实现强大的功能,使代码更优雅。
以前的版本是对 selenium 进行重新封装实现的。从 3.0 开始,作者另起炉灶,对底层进行了重新开发,摆脱对 selenium 的依赖,增强了功能,提升了运行效率。
1 | from DrissionPage import ChromiumPage |